基于Lucene实现全文检索
实验概述
【实验目的】
使用Lucene建立索引,使用包括37,600新闻文章的TDT3数据集,编写一个命令行搜索引擎。输入关键词与数量可以返回对应个数与关键词最相关的新闻文章,并输出文档相关性的得分。
【实验环境】
实验平台:IntelLij IDEA 2024.1.1
Java环境:Jdk 17.0.6
检索工具:Lucene 8.11.3
【参考资料】
[1] 最详细的Lucene实现全文检索
[2] Java教程
[4] 全文检索工具Lucene入门教程
[5] lucene全文检索原理和流程
实验内容
【实验方案设计】
实验原理
一、全文检索
数据可分为结构化数据和非结构化数据,对数据查询时,结构化数据可以通过 SQL 语句等方式查询,而非结构化数据(如PPT,word等)无法用此方式查询,需利用将非结构化数据转化为结构化数据(即先将文件中单词按空格拆分,把单词创建创建一个索引表,然后查询索引,根据单词和文档的关系找到文档列表,即全文检索),进行快速查询。先创建索引,然后查询索引的过程是全文检索,具有一次创建,多次使用的特点(创建的速度有点慢)。在搜索引擎百度、360、google、bing,站内搜索论坛、CSDN、文章搜索,电商搜索淘宝、京东、软件内的搜索中均有应用。
二、Lucene介绍
Lucene是开放源代码的全文检索引擎工具包,主要有创建索引和查询索引两个步骤。
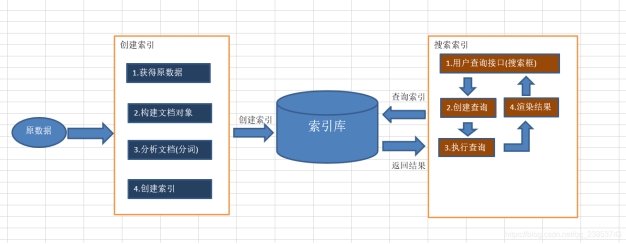
- 创建索引
采集信息:从数据库、互联网、爬虫、word等方式获取原始文档。
构建索引文档:对应每个原始文档创建一个Document对象(拥有唯一的ID),每个Document中包含多个Field,不同的Document可以有不同的Field,同一Document可以有相同的Field域中以键值对保存域的名称和值。

分析文档(分词):对原始文档提取单词、将字母转为小写、去除标点符号、去除停用词等过程生成最终的语汇单元,可以将语汇单元都是一个单词:
The Spring Framework provides a comprehensive programming and configuration model.
Spring、Framework、programming、model是一个个Term,不同的域中拆分出来的相同的单词是不同的term,term中包含两部分一部分是文档的域名,另一部分是单词的内容。
创建索引:基于关键词创建一个索引,保存到索引库中:
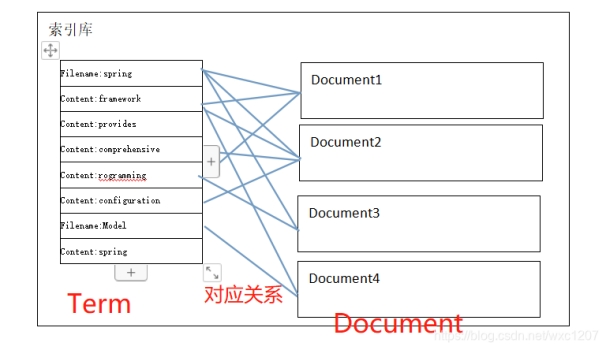
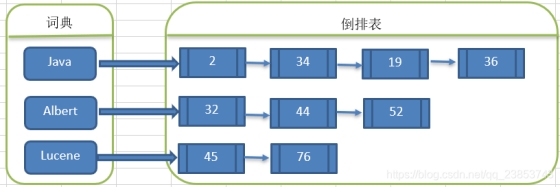
通过词语找文档,这种索引的结构叫倒排索引结构:
- 查询索引
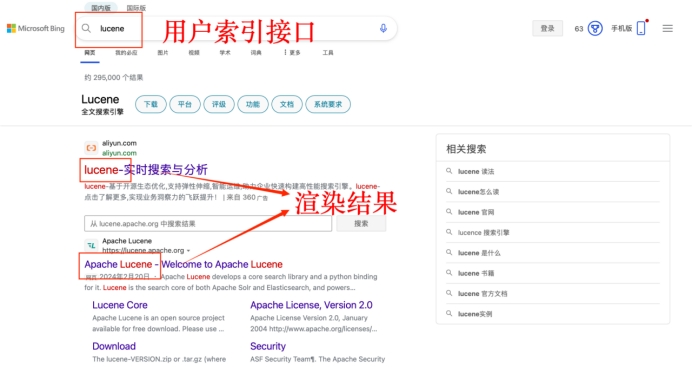
用户查询接口:
创建查询:创建查询对象Query,将需要查询的内容Term输入进去,进行查询。
执行查询:根据对应搜索词的索引,从而找到索引所链接的文档链表。
渲染结果:搜索词如上图进行高亮显示。
三、Lucene demo
lucene可以利用官方提供的demo,直接在终端创建索引并进行简单的检索。
- 安装lucene
下载合适版本的lucene,将核心包、展示包和查询包的jar文件解压以便使用:
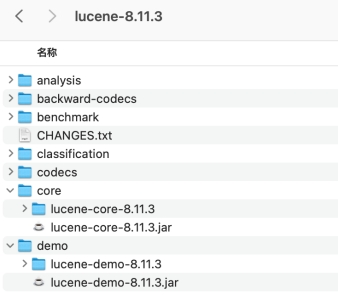

将路径加入到配置文件:
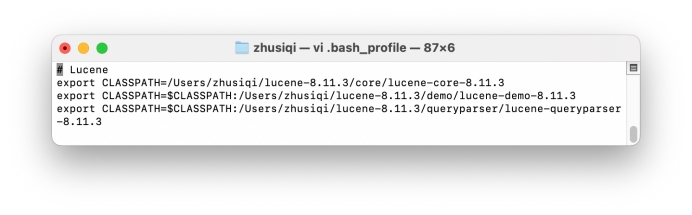
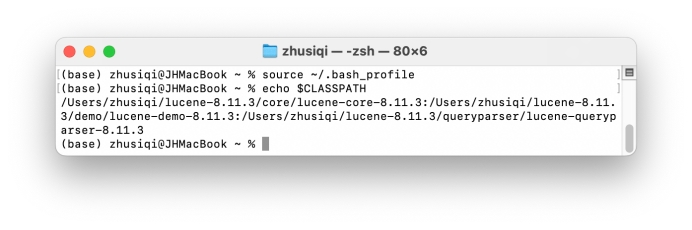
重启终端后查看lucene相关软件包的路径添加成功:
配置jdk环境:

使用lucene创建索引tdt3:
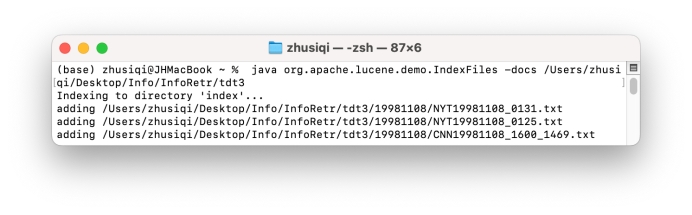
进行全文检索:
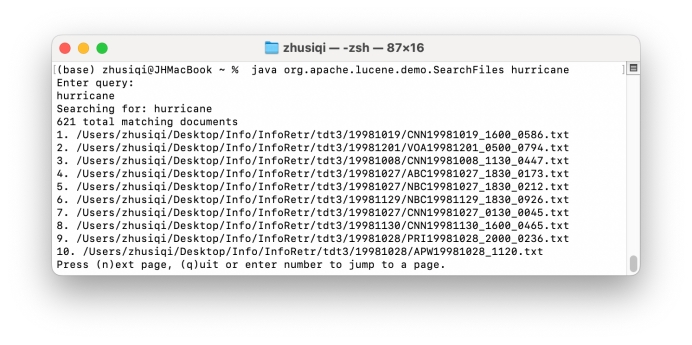
简单的demo可以在检索目录中得到文章路径。
详细设计
为了开发更丰富的效果,接下来将利用lucene在IDEA中进行开发。
一、配置Maven
下载对应的Maven版本:
配置路径:
Maven安装完成:
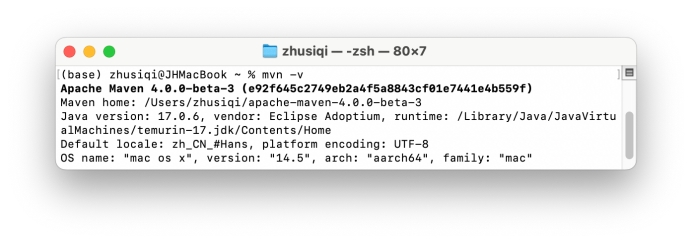
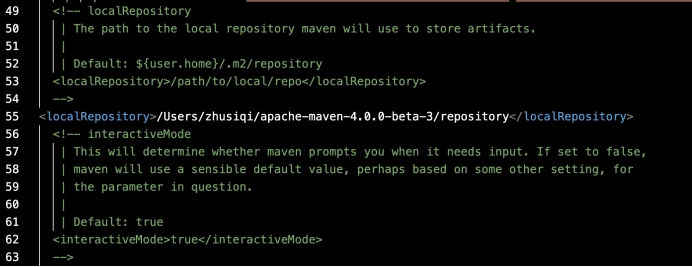
在conf/settings.xml中修改jar扩展路径:
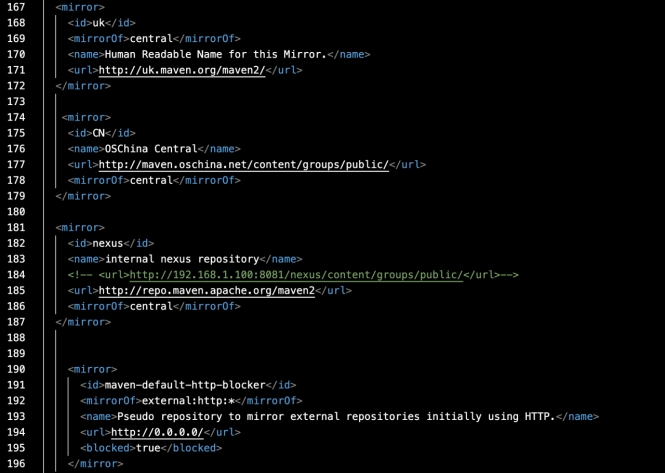
因为下载jar包地址不太稳定,换成国内的镜像地址,在
下载jar包到本地仓库mvn help:system,配置完成:
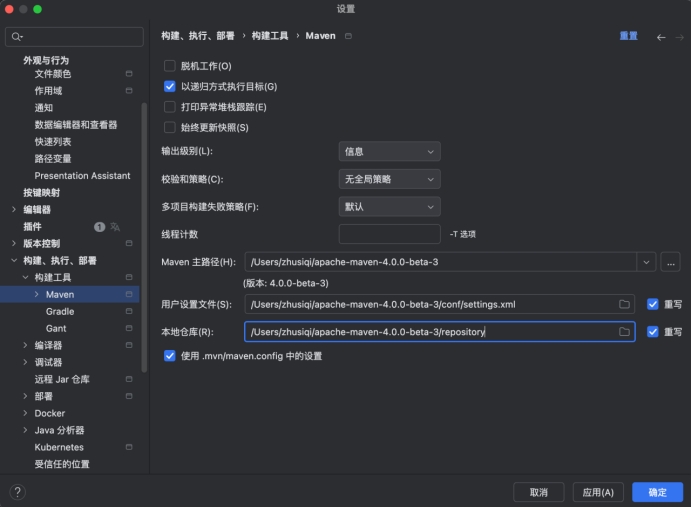
在IDEA选择该环境:
在Java环境即可创建简单的Maven项目:
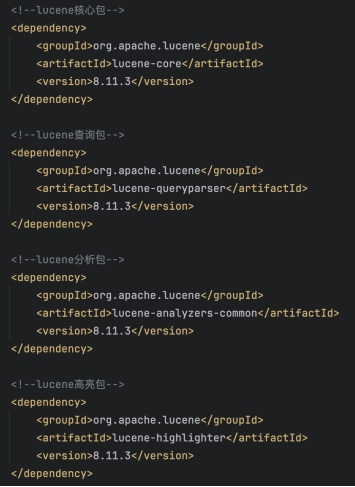
在pom.xml中导入扩展包:
Maven环境配置完成。
二、项目设计
删除test、org等无关文件,将tdt3放入项目根目录,创建index目录用于存储索引,在java文件夹下创建bean、engine和utils,分别用于文档信息的封装、集成函数创建索引或进行检索、实现相关工具。
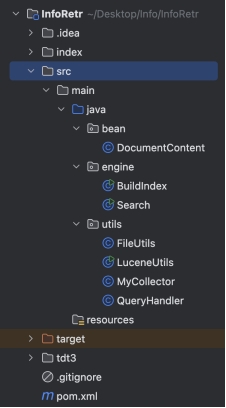
核心算法说明及分析
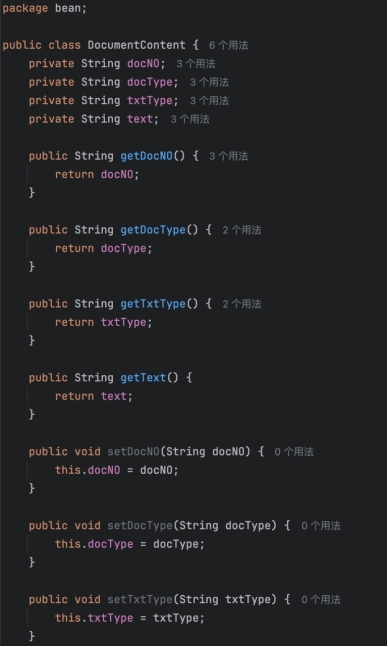
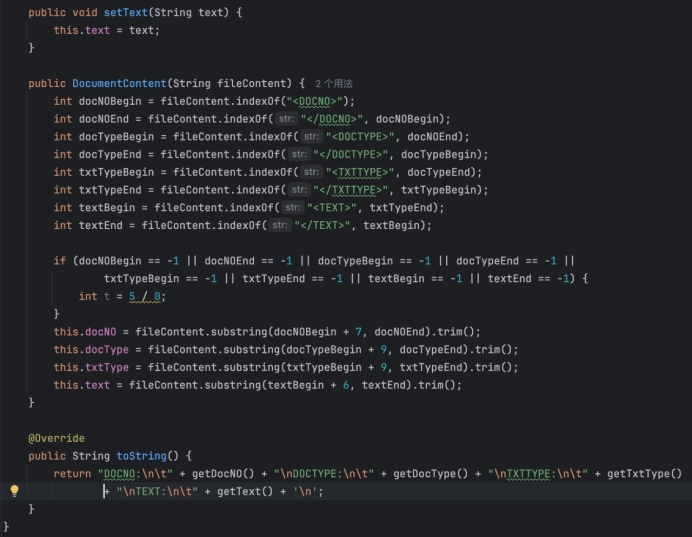
一、DocumentContent.java
用于解析和存储文档内容,即从一个包含特定标签的字符串中解析出文档的各种信息,并提供这些信息的访问和修改接口。
-
属性定义:
-
docNO:文档编号。
-
docType:文档类型。
-
txtType:文本类型。
-
text:文档的实际文本内容。
-
-
构造函数:
- 输入参数为 fileContent,即包含文档信息的字符串。
- 通过查找特定的标签(如
, , , 及其对应的结束标签),从 fileContent 中解析出文档的编号、类型、文本类型和实际文本。 - 如果任何标签未找到(即返回 -1),则会通过 int t = 5 / 0,抛出一个除以零的异常。
-
Getter 和 Setter 方法:
- 为每个属性提供标准的 getter 和 setter 方法,允许外部获取和设置这些属性的值。
-
toString 方法:
- 重写Object 类的 toString 方法,用于生成包含所有文档内容的格式化字符串,便于打印和查看。
二、FileUtils.java
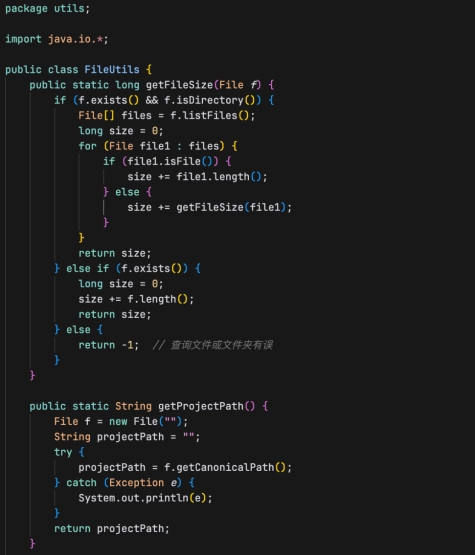
用于处理文件和文件夹的常见操作,适用于需要文件大小、项目路径或文件内容的场景:
- getFileSize(File f): 用于计算一个文件或文件夹的大小(以字节为单位)。
- 参数: File f - 表示要计算大小的文件或文件夹。
- 返回值: long - 文件或文件夹的大小,如果文件不存在则返回-1。
- 算法逻辑:
(1)首先检查文件是否存在且是否为目录(文件夹)。
(2)如果是目录,遍历目录中的所有文件和子目录。
(3)对于每个文件,直接累加其大小。
(4)对于每个子目录,递归调用getFileSize方法并累加返回的大小。
(5)如果是文件,直接返回文件的大小。
(6)如果文件或目录不存在,返回-1,表示错误。
- getProjectPath():用于获取当前Java项目的路径。
- 返回值: String - 项目的完整路径。
- 算法逻辑:
(1)创建一个指向当前目录的File对象。
(2)使用getCanonicalPath方法获取规范化的绝对路径。
(3)如果在获取路径过程中发生异常,捕获异常并打印。
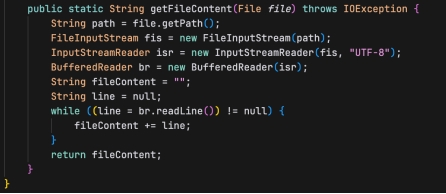
- getFileContent(File file):读取文件内容并以字符串形式返回。
- 参数: File file - 要读取内容的文件。
- 返回值: String - 文件的内容。
- 异常: 抛出IOException,处理文件读取时可能出现的输入输出异常。
- 算法逻辑:
(1)通过文件路径创建FileInputStream。
(2)使用InputStreamReader将字节流转换为字符流,并指定字符集为"UTF-8"。
(3)使用BufferedReader逐行读取文件内容,将所有行累加到一个字符串中。
(4)返回最终累加的字符串。
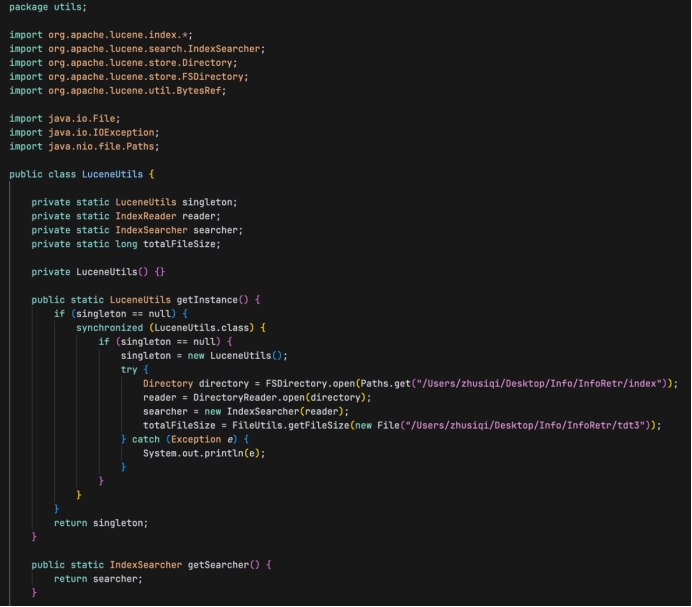
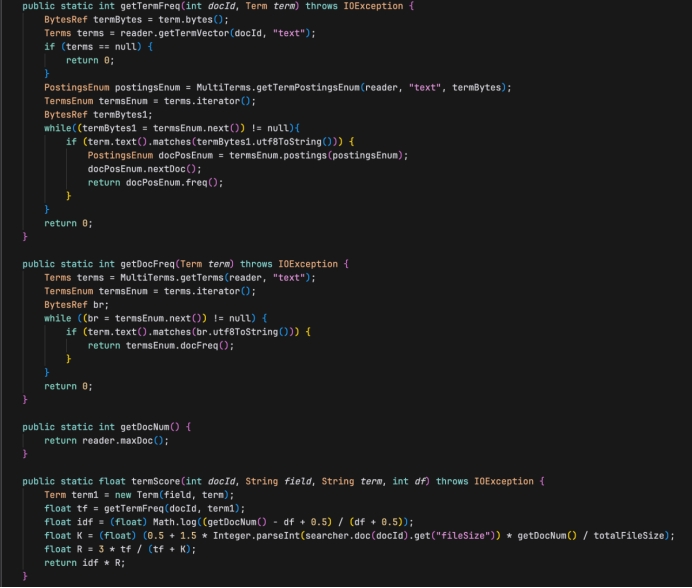
三、LuceneUtils.java
创建管理Lucene的索引读取器(IndexReader)和搜索器(IndexSearcher),并提供一些静态方法来获取文档频率、词频并计算词项得分:
-
类和字段
- LuceneUtils:一个工具类,包含了与Lucene索引交互的方法。
- singleton:该类的单例实例。
- reader:用于读取索引的IndexReader对象。
- searcher:用于在索引上执行搜索的IndexSearcher对象
- totalFileSize:索引中所有文档的总文件大小。
-
构造方法
- private LuceneUtils():私有构造函数,防止外部直接实例化。
-
方法
- getInstance():单例模式的实现。如果singleton为空,则初始化它,并创建Directory和IndexReader,以及IndexSearcher。同时计算总文件大小。
- getSearcher():返回IndexSearcher对象。
- getTermFreq(int docId, Term term):获取指定文档ID和词项的词频。如果词项在文档中不存在,则返回0。
- getDocFreq(Term term):获取一个词项在所有文档中的文档频率。
- getDocNum():返回索引中的文档总数。
- termScore(int docId, String field, String term, int df):计算一个词项在特定文档中的得分,使用了TF-IDF模型和BM25模型的一部分。
-
主函数
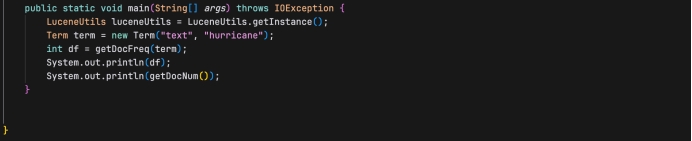
- main(String[] args):程序入口点。创建LuceneUtils的实例,查询词项"hurricane"的文档频率和索引中的文档总数,并打印这些信息。
-
错误处理
- 在getInstance()方法中,使用了try-catch块来处理可能的异常,如文件路径错误或读取错误。
四、MyCollector.java
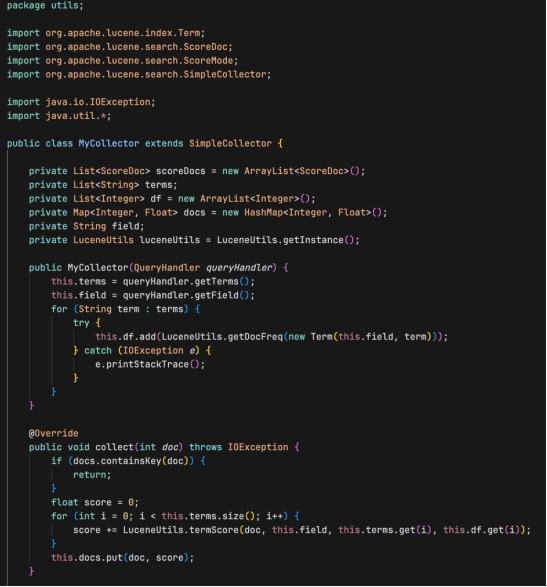
继承自 Lucene 的 SimpleCollector 类,用于自定义文档收集过程,可以根据特定的需求调整搜索结果的排序和处理:
-
类定义和成员变量
- MyCollector 类扩展了 Lucene 的 SimpleCollector 类。
- scoreDocs:存储搜索结果的 ScoreDoc 对象列表。
- terms:搜索查询中涉及的术语列表。
- df:每个术语的文档频率(document frequency)列表。
- docs:一个映射,键是文档ID,值是该文档的得分。
- field:搜索的字段。
- luceneUtils:一个 LuceneUtils 的实例,用于执行与 Lucene 相关的操作。
-
构造函数
- 构造函数接收一个 QueryHandler 对象,从中获取搜索的术语和字段。
- 对于每个术语,使用 LuceneUtils.getDocFreq 方法获取其在指定字段中的文档频率,并捕获可能的 IOException。
-
方法 collect
- collect 方法是在处理每个文档时调用的。
- 如果文档已经在 docs 映射中,则直接返回。
- 否则,计算该文档的得分,得分是基于每个术语的得分(通过 LuceneUtils.termScore 方法计算)的总和,并将结果存储在 docs 映射中。
-
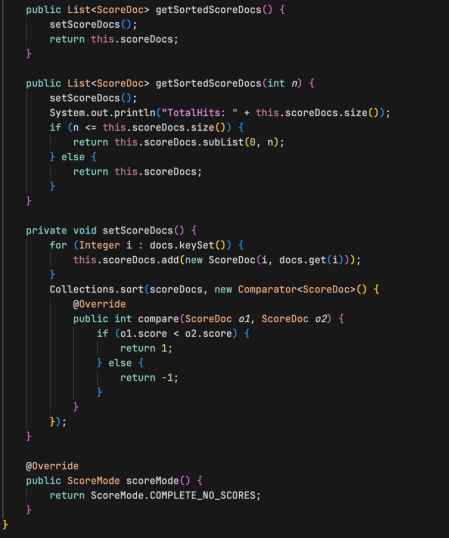
方法 getSortedScoreDocs
- getSortedScoreDocs 方法返回排序后的 ScoreDoc 列表。
- setScoreDocs 方法首先将 docs 映射中的每个条目转换为 ScoreDoc 对象,并添加到 scoreDocs 列表中。
- 然后使用 Collections.sort 对 scoreDocs 排序,排序依据是 ScoreDoc 的得分。
-
方法 getSortedScoreDocs(int n)
- getSortedScoreDocs 的重载版本,它接受一个整数 n,表示要返回的最大文档数。
- 如果 n 小于或等于 scoreDocs 的大小,则返回前 n 个文档;否则,返回所有文档。
-
方法 scoreMode
- scoreMode 方法指定了收集器的得分模式,这里设置为 ScoreMode.COMPLETE_NO_SCORES,意味着不需要文档得分。
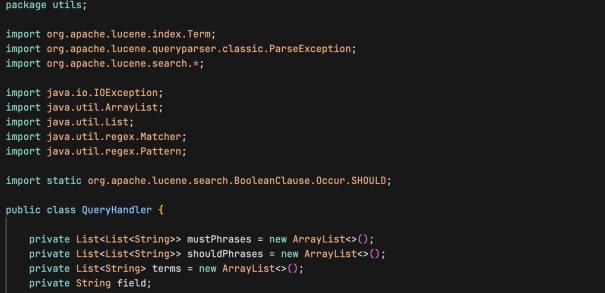
五、QueryHandler.java
处理基于文本的查询,并生成对应的 Lucene 查询对象:
-
类属性
- mustPhrases: 存储必须出现的短语列表,每个短语由一个字符串列表表示。
- shouldPhrases: 存储应该出现的短语列表,每个短语由一个字符串列表表示。
- terms: 存储单独的搜索词。
- field: 搜索字段的名称。
-
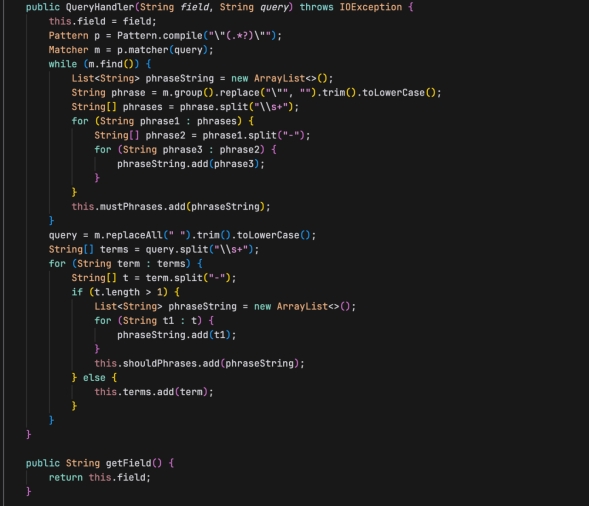
构造函数
- 参数:field (搜索字段名), query (查询字符串)。
- 功能:解析输入的查询字符串,区分出必须出现的短语(用双引号包围)、应该出现的短语(包含连字符的词组)和普通的搜索词。这些元素被存储在相应的类属性中。
-
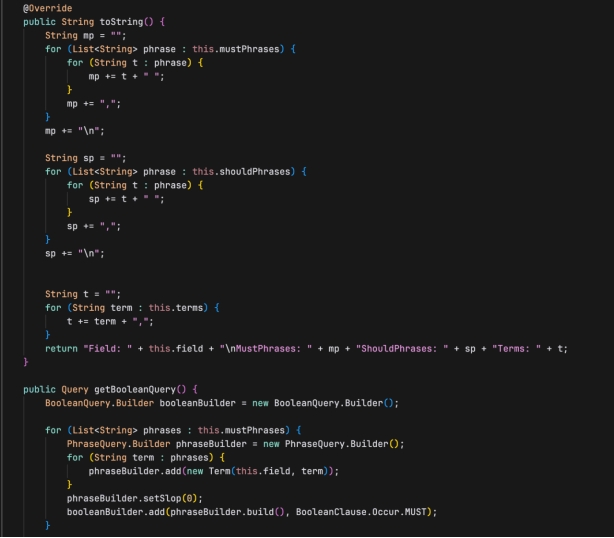
方法
- getField(): 返回搜索字段名。
- toString(): 返回类的字符串表示,包括搜索字段、必须出现的短语、应该出现的短语和搜索词。
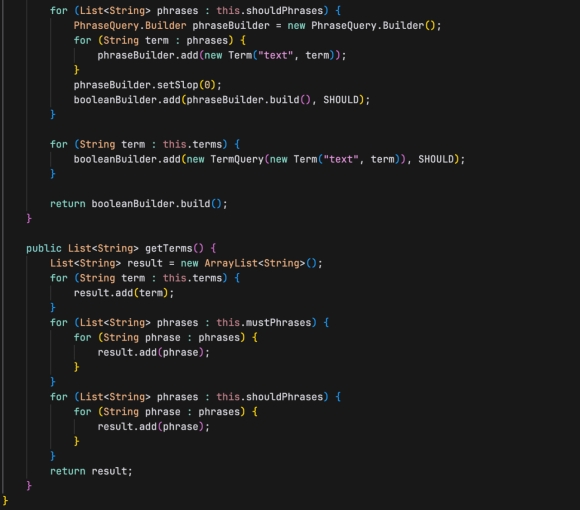
- getBooleanQuery(): 构建并返回一个 Lucene 的 BooleanQuery 对象,该查询对象结合了必须出现的短语、应该出现的短语和搜索词,以构建复杂的搜索逻辑。
- getTerms(): 返回所有搜索词和短语的列表。
-
查询处理逻辑
(1)解析必须出现的短语:使用正则表达式从查询中提取被双引号包围的短语,去除引号并拆分为单词列表。
(2)处理剩余查询:从原始查询中移除已处理的短语,剩余部分进一步拆分为单词。
(3)区分应该出现的短语和普通搜索词:对剩余单词进行处理,含连字符的视为短语,否则视为普通搜索词。
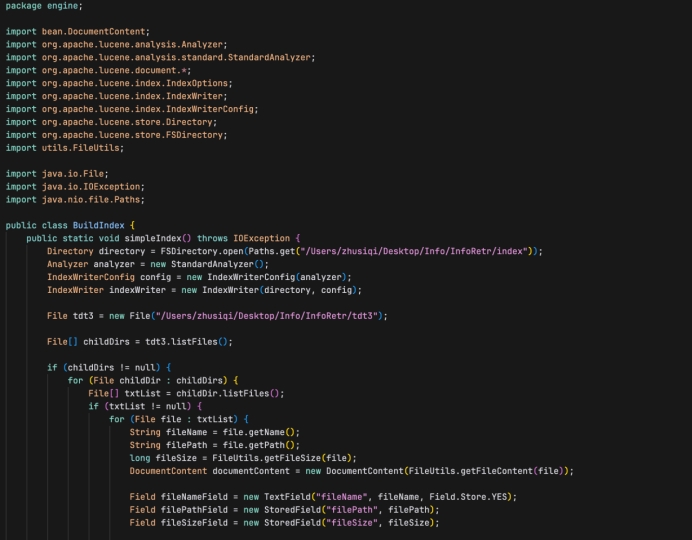
六、BuildIndex.java
使用Apache Lucene库来创建一个文本文件的索引,读取一个文件夹中的所有文本文件,并将它们的内容及一些元数据添加到Lucene索引中,即通过递归遍历指定目录下的所有文件,并将它们的内容及元数据索引化,从而使得这些文档可以被Lucene快速检索:
-
导入必要的库和类:
- DocumentContent:自定义类,用于处理文档内容。
- Analyzer, StandardAnalyzer, Document, Field, IndexWriter 等:这些是Lucene库中用于文本分析和索引构建的类。
-
类和方法定义:
- BuildIndex 类包含了索引构建的方法。
- simpleIndex 方法是静态的,可以直接通过类名调用,用于创建索引。
-
设置索引存储路径和分析器:
- 使用 FSDirectory.open 方法设置索引的存储目录。
- StandardAnalyzer 用于分析文本(如分词)。
-
读取文件:
- 代码读取指定目录下的所有文件和子目录。
- 对于每个文件,读取其名称、路径和大小。
-
读取和处理文档内容:
- 使用 FileUtils.getFileContent 方法读取文件内容。
- DocumentContent 类用于解析文档内容,获取文档编号、类型等信息。
-
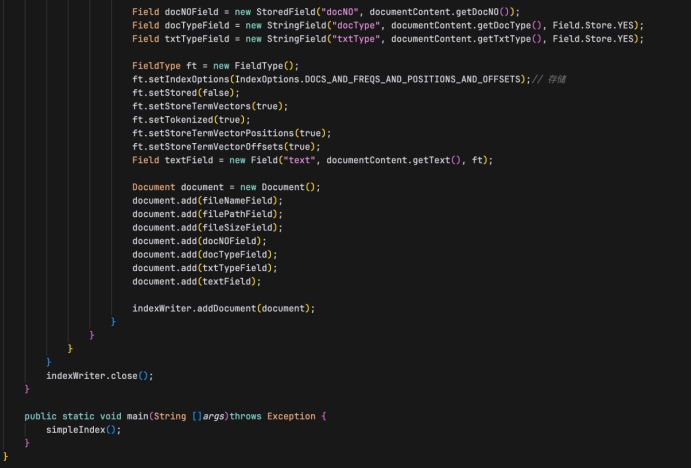
创建Lucene文档并添加字段:
- 为每个文件创建一个 Document 对象。
- 添加各种字段到文档中,如文件名、路径、大小、文档编号、文档类型等。
- FieldType 设置用于控制字段的索引方式,如是否存储位置、偏移量等。
-
将文档添加到索引中:
- 使用 IndexWriter 将每个 Document 对象添加到索引中。
-
关闭IndexWriter:
- 完成所有文档的添加后,关闭 IndexWriter 以保存索引并释放资源。
-
主方法:
- main方法调用 simpleIndex 方法来执行索引构建过程。
七、Search.java
从用户输入中接收搜索命令和参数,然后执行搜索并显示结果:
-
导入必要的库和类:
- Document, Query, ScoreDoc 等来自 Lucene 库,用于处理文档和搜索查询。
- FileUtils, LuceneUtils, MyCollector, QueryHandler 是自定义的工具类,用于文件操作、Lucene 操作、自定义结果收集和查询处理。
-
主类和主方法:
- Search 类包含了 main 方法,这是程序的入口点。
-
用户输入处理:
- 程序首先提示用户输入一个搜索命令,格式为 search --hits=
。 - 如果输入不以 “search” 开头,程序会输出错误信息并退出。
- 程序首先提示用户输入一个搜索命令,格式为 search --hits=
-
解析命令和参数:
- 从用户输入中提取关键词和提取数(hits)。如果没有指定 --hits 参数,默认为10。
- 使用字符串操作来分离关键词和命中数。
-
初始化 Lucene 工具和查询处理器:
- LuceneUtils.getInstance() 初始化 Lucene 工具。
- QueryHandler 类用于生成基于用户关键词的布尔查询。
-
执行搜索:
- 使用 LuceneUtils.getSearcher() 获取一个搜索器。
- 搜索器执行查询,并使用 MyCollector 来收集结果。
-
处理和显示搜索结果:
- 对于每个搜索结果,程序读取文档的路径,打开文件,并提取文档内容。如果文档内容少于400字符,直接显示;
- 如果超过400字符,显示前400字符并附加省略号。
- 显示每个结果的序号、得分、文档编号和摘要。
【实验结果】
运行BuildIndex.java创建索引:

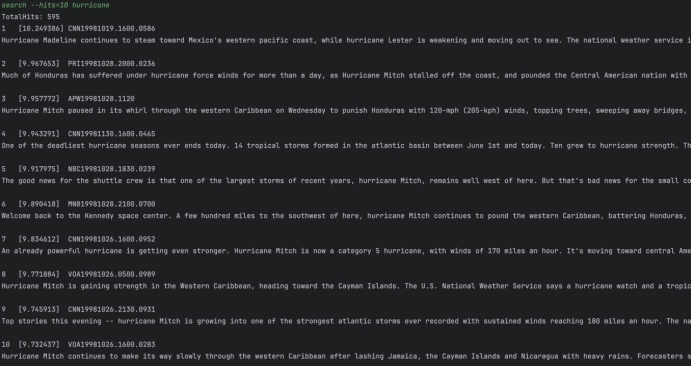
运行Search.java进行全文检索:
Q1: hurricane
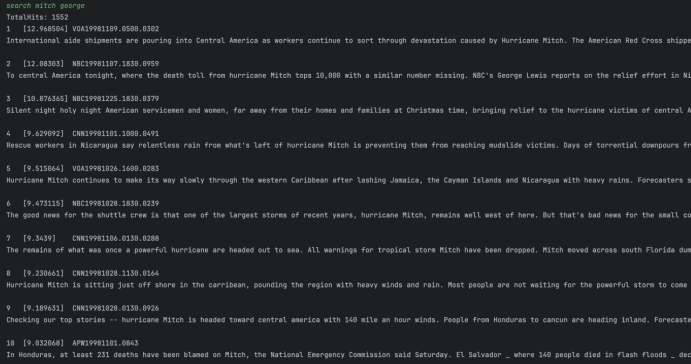
Q2: mitch george
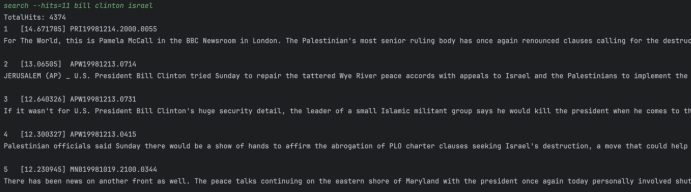
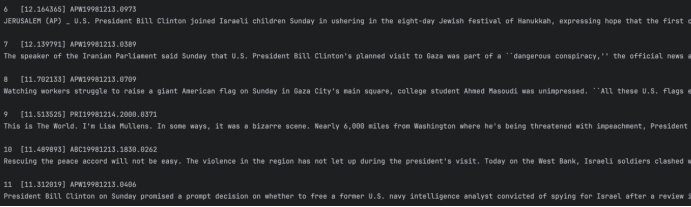
Q3: billclinton israel
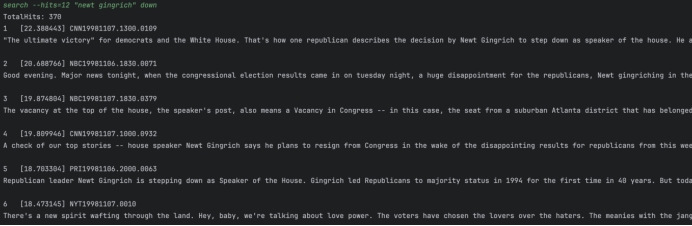
Q4: “newt gingrich” down
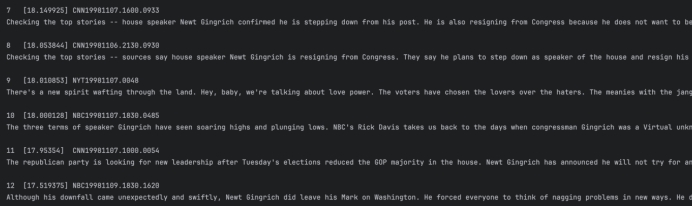
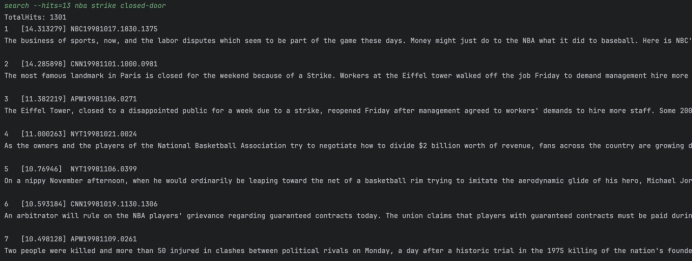
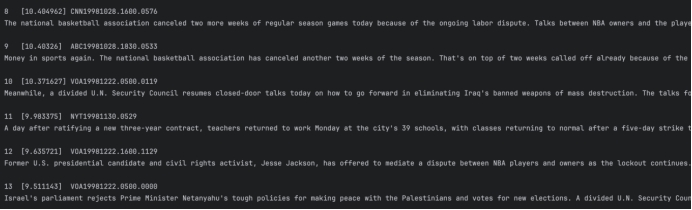
Q5: nba strike closed-door
实验小结
在本次信息检索大实验中,我使用Lucene作为索引构建工具,在TDT3数据集中创建索引并进行检索。我编写了一个命令行搜索引擎,该引擎可以根据用户输入的关键词和数量N返回最相关的N篇新闻文章,输出文档相关性的得分,并能够进行词干处理、忽略大小写、忽略数字以及忽略标点符号(包括连字符)。
在实验的过程中,我深刻感受到了索引构建工具的选择对信息检索系统的性能至关重要。Lucene提供了强大的索引和搜索功能,能够高效地处理大规模文本数据集。同时,相关性得分对搜索结果的排序非常重要。Lucene提供了基于文本匹配算法的相关性得分计算,通过得分可以对搜索结果进行排序,使用户更容易找到与其查询相关的文章。
通过这次实验,我深入了解了Lucene的使用和搜索引擎的基本原理。同时,我也认识到了在构建和设计信息检索系统时需要考虑到用户需求、搜索算法和结果展示等方面的因素,对我的学习有很大的帮助。
项目代码
 支付宝
支付宝




