from haystack.components.preprocessors import NLTKDocumentSplitter, DocumentSplitter from haystack import Document
text = """The dog was called Wellington. It belonged to Mrs. Shears who was our friend. She lived on the opposite side of the road, two houses to the left.""" document = Document(content=text)
simple: document_0: The dog was called Wellington. document_1: It belonged to Mrs. document_2: Shears who was our friend. document_3: She lived on the opposite side of the road, two houses to the left.
nltk: document_0: The dog was called Wellington. document_1: It belonged to Mrs. Shears who was our friend. document_2: She lived on the opposite side of the road, two houses to the left.
document_store = InMemoryDocumentStore() documents = [ Document(content="There are over 7,000 languages spoken around the world today."), Document(content="Elephants have been observed to behave in a way that indicates a high level of self-awareness, such as recognizing themselves in mirrors."), Document(content="In certain parts of the world, like the Maldives, Puerto Rico, and San Diego, you can witness the phenomenon of bioluminescent waves.") ] document_store.write_documents(documents=documents) retriever = InMemoryBM25Retriever(document_store=document_store) docs = retriever.run(query="How many languages are spoken around the world today?")["documents"] for doc in docs: print(f"content: {doc.content}") print(f"score: {doc.score}")
输出:
1 2 3 4 5 6
content: There are over 7,000 languages spoken around the world today. score: 7.815769833242408 content: In certain parts of the world, like the Maldives, Puerto Rico, and San Diego, you can witness the phenomenon of bioluminescent waves. score: 4.314753296196667 content: Elephants have been observed to behave in a way that indicates a high level of self-awareness, such as recognizing themselves in mirrors. score: 3.652595952218814
query = "How many languages are there?" result = query_pipeline.run({"text_embedder": {"text": query}}) result_documents = result["retriever"]["documents"] for doc in result_documents: print(f"content: {doc.content}") print(f"score: {doc.score}\n")
输出
1 2 3 4 5 6 7 8
content: There are over 7,000 languages spoken around the world today. score: 0.7557791972968138
content: Elephants have been observed to behave in a way that indicates a high level of self-awareness, such as recognizing themselves in mirrors. score: 0.04221229186262071
content: In certain parts of the world, like the Maldives, Puerto Rico, and San Diego, you can witness the phenomenon of bioluminescent waves. score: -0.001667825878752048
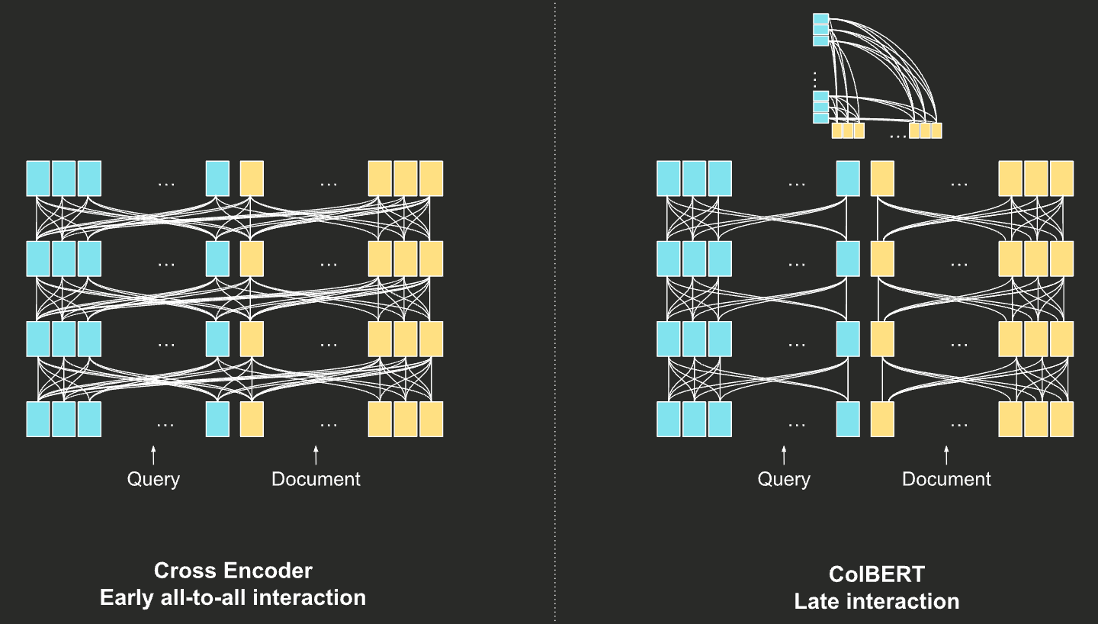
cross vs. colbert: 词元向量的交互从相似度计算阶段(colbert),提前到BERT模型内部(cross)
例子
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
from haystack import Document from haystack.components.rankers import TransformersSimilarityRanker
documents = [ Document(content="There are over 7,000 languages spoken around the world today."), Document(content="Elephants have been observed to behave in a way that indicates a high level of self-awareness, such as recognizing themselves in mirrors."), Document(content="In certain parts of the world, like the Maldives, Puerto Rico, and San Diego, you can witness the phenomenon of bioluminescent waves."), ] ranker = TransformersSimilarityRanker(model="cross-encoder/ms-marco-MiniLM-L-6-v2") ranker.warm_up() query = "How many languages are there?" ranked_documents = ranker.run(query=query, documents=documents)["documents"] for doc in ranked_documents: print(f"content: {doc.content}") print(f"score: {doc.score}\n")
输出
1 2 3 4 5 6 7 8 9 10
content: There are over 7,000 languages spoken around the world today. score: 0.9998884201049805
content: Elephants have been observed to behave in a way that indicates a high level of self-awareness, such as recognizing themselves in mirrors. score: 1.4616251974075567e-05
content: In certain parts of the world, like the Maldives, Puerto Rico, and San Diego, you can witness the phenomenon of bioluminescent waves. score: 1.4220857337932102e-05
from prompt_toolkit import prompt from haystack import Pipeline from haystack.utils import Secret from haystack.document_stores.in_memory import InMemoryDocumentStore from haystack.components.fetchers import LinkContentFetcher from haystack.components.converters import HTMLToDocument from haystack.components.preprocessors import DocumentSplitter from haystack.components.writers import DocumentWriter from haystack.components.retrievers.in_memory import InMemoryEmbeddingRetriever from haystack.components.generators import OpenAIGenerator from haystack.components.builders.prompt_builder import PromptBuilder from haystack.components.embedders import ( SentenceTransformersTextEmbedder, SentenceTransformersDocumentEmbedder,)
The motto of Nanjing University is “诚朴雄伟励学敦行,” which translates to “Sincerity with Aspiration, Perseverance and Integrity” in English. The first half of this motto was the motto during the National Central University time, and the last half was quoted from the classic literature work Book of Rites.
What is the song of Nanjing University?
The song of Nanjing University is the university song, which was created in 1916. It is the first school song in the modern history of Nanjing University. The lyrics were written by Jiang Qian, and the melody was composed by Li Shutong. The song was recovered in 2002.
问一些大模型不知道的问题
question: Who is the modern China’s first PhD in Chinese Language and Literature?
Chatgpt answer
一会说1986年的郭齐勇,一会说1983年的陈平原
RAG answer
The modern China’s first PhD in Chinese Language and Literature is Mo Lifeng (莫砺锋), as mentioned in the documents.
from haystack import Document, Pipeline from haystack.document_stores.in_memory import InMemoryDocumentStore from haystack.components.embedders import ( SentenceTransformersTextEmbedder, SentenceTransformersDocumentEmbedder, ) from haystack.components.retrievers.in_memory import InMemoryBM25Retriever from haystack.components.retrievers import InMemoryEmbeddingRetriever from haystack.components.joiners.document_joiner import DocumentJoiner
query = "What are effective strategies to improve English speaking skills?" documents = [ Document(content="Practicing with native speakers enhances English speaking proficiency."), Document(content="Regular participation in debates and discussions refine public speaking skills in English."), Document(content="Studying the history of the English language does not directly improve speaking skills."), ]
bm25_retriever = InMemoryBM25Retriever(document_store=document_store,scale_score=True) bm25_docs = bm25_retriever.run(query=query)["documents"] print("bm25:") for doc in bm25_docs: print(f"content: {doc.content}") print(f"score: {doc.score}\n")
输出
1 2 3 4 5 6 7 8
content: Studying the history of the English language does not directly improve speaking skills. score: 0.5593245377361279 content: Regular participation in debates and discussions refine public speaking skills in English. score: 0.545159185512614 content: Practicing with native speakers enhances English speaking proficiency. score: 0.5387709786621966
content: Practicing with native speakers enhances English speaking proficiency. score: 0.8296398226909952
content: Regular participation in debates and discussions refine public speaking skills in English. score: 0.8017774366152697
content: Studying the history of the English language does not directly improve speaking skills. score: 0.7334273104138469
权重合并
1 2 3 4 5
joiner = DocumentJoiner(join_mode="merge", weights=[0.3, 0.7]) merge_docs = joiner.run(documents=[bm25_docs, dense_docs])["documents"] for doc in merge_docs: print(f"content: {doc.content}") print(f"score: {doc.score}\n")
输出
1 2 3 4 5 6 7 8
content: Practicing with native speakers enhances English speaking proficiency. score: 0.7423791694823556 content: Regular participation in debates and discussions refine public speaking skills in English. score: 0.724791961284473 content: Studying the history of the English language does not directly improve speaking skills. score: 0.6811964786105311
RRF合并
1 2 3 4 5 6
joiner = DocumentJoiner(join_mode="reciprocal_rank_fusion") rrf_docs = joiner.run(documents=[bm25_docs,dense_docs])["documents"] print("rrf:") for doc in rrf_docs: print(f"content: {doc.content}") print(f"score: {doc.score}\n")
输出
1 2 3 4 5 6 7 8
content: Studying the history of the English language does not directly improve speaking skills. score: 0.9841269841269842 content: Practicing with native speakers enhances English speaking proficiency. score: 0.9841269841269842 content: Regular participation in debates and discussions refine public speaking skills in English. score: 0.9838709677419354
from haystack import Document from haystack.document_stores.in_memory import InMemoryDocumentStore from haystack.components.retrievers.in_memory import InMemoryBM25Retriever from haystack.components.rankers import TransformersSimilarityRanker
query = "What are effective strategies to improve English speaking skills?" documents = [ Document( content="Practicing with native speakers enhances English speaking proficiency." ), Document( content="Daily vocabulary expansion is crucial for improving oral communication skills." ), Document( content="Engaging in language exchange programs can significantly boost speaking abilities." ), Document( content="Regular participation in debates and discussions refine public speaking skills in English." ), Document( content="Studying the history of the English language does not directly improve speaking skills." ), ] document_store = InMemoryDocumentStore() document_store.write_documents(documents)
bm25初步检索
1 2 3 4 5 6
bm25_retriever = InMemoryBM25Retriever(document_store=document_store) bm25_docs = bm25_retriever.run(query=query, top_k=4)["documents"] print("bm25:") for doc in bm25_docs: print(f"content: {doc.content}") print(f"score: {doc.score}\n")
输出
1 2 3 4 5 6 7 8 9 10 11 12
bm25: content: Studying the history of the English language does not directly improve speaking skills. score: 3.1117211646172698
content: Regular participation in debates and discussions refine public speaking skills in English. score: 2.443788686074245
content: Practicing with native speakers enhances English speaking proficiency. score: 2.2622329312889553
content: Daily vocabulary expansion is crucial for improving oral communication skills. score: 2.0359854825047066
重排序
1 2 3 4 5 6 7
reranker = TransformersSimilarityRanker(model="cross-encoder/ms-marco-MiniLM-L-6-v2") reranker.warm_up() reranked_docs = reranker.run(query=query, documents=bm25_docs, top_k=3)["documents"] print("reranker:") for doc in reranked_docs: print(f"content: {doc.content}") print(f"score: {doc.score}\n")
输出
1 2 3 4 5 6 7 8 9 10 11
reranker: content: Practicing with native speakers enhances English speaking proficiency. score: 0.769904375076294
content: Studying the history of the English language does not directly improve speaking skills. score: 0.5486361384391785
content: Daily vocabulary expansion is crucial for improving oral communication skills. score: 0.3509156107902527




 支付宝
支付宝

